
by SX Engineering
10 min read
by SX Engineering
10 min read

Our journey towards building a cloud-native, real-time DXP composability has been anything but straightforward. It's still a learning process, where every problem we encounter becomes a lesson that helps us improve the platform.
We were reminded of this in early June, when we received a notification about a $900 increase in costs for our own StreamX environment. The amount itself wasn't that alarming, but the cost forecast was. It was predicted to reach $9,000 next month and double every month thereafter. This upward trend was worrying, because it could potentially impact our development budget.

Our monthly cost before and after optimization
In this article, we will explain why this happened, how we managed to solve the issue in both short and long term, and how we learned from this event to improve our platform.
The increase in costs was mainly linked to the fact that with a real-time platform, the number of processed operations can become really large, really quickly. StreamX is a web-scale platform that can process millions of messages per second.

StreamX speed at scale metrics
When you are an engineer dealing with a high-throughput system, you encounter problems that weren't issues in traditional setups, because they simply can’t handle such a large amount of data.
In our case, the main contributor was log data, which accounted for almost half of the total expenses. Costs like these, as we experienced firsthand, can grow pretty exponentially. If you log a single line for every message, and receive a hundred million messages, you end up with terabytes of log files that you need to pay for.
This wouldn't have been a scenario in a traditional platform like a monolithic DXP, because it would have taken up to 24 hours to generate that much log data. But don't be fooled - that doesn't mean the monoliths are cost-effective, especially by the cloud-native standards.
When developing an enterprise monolithic platform, we must always start with planning for the worst-case scenario, as these platforms do not scale easily. Scaling becomes a manual process involving the engineering and infrastructure teams. They set up new servers, configure them, and replicate data. The larger the platform becomes, the less efficient any attempts on automation are.
Instance multiplying - a popular way to scale the monolith
In contrast, StreamX’s system and infrastructure were designed to be cloud-native and automatically scalable. This flexibility allows for both upward and downward adjustments, resulting in a highly flexible and adaptable architecture. This way we can naturally respond to traffic fluctuations, accommodating both anticipated future growth. Our focus shifted from solely accommodating the highest possible traffic to effectively handling the actual traffic, dynamically scaling resources as needed. StreamX was designed for scalability (support increasing traffic in the future with a constant rate of errors, etc.) and elasticity (be able to support local bursts of traffic) in mind. The ability to scale the costs is a consequence of architectural decisions we made.
However, it wasn't our ultimate goal to make the cheapest platform possible. Cost is always a factor, but more often than not, it is an outcome of the practices executed around the implementation of cloud-native applications.
When discussing the cost of running the platform, it's important to consider more than just the day-to-day expenses. The total cost of ownership comes from three distinct categories: infrastructure, operational, and business costs. Infrastructure costs cover servers, disks, and network expenses; operational costs involve personnel management and monitoring; business costs are associated with potential problems that may lead to data loss, fines due to failures, or loss of customer trust.

Similarly, the 4 factors that we prioritized during the StreamX development process:
scalability
interoperability
extensibility
throughput/performance
affect not only the infrastructure costs. By giving priority to these aspects, we can achieve higher efficiency and performance, resulting in reduced overall operational and business costs over time.
Our decision to build in the cloud was motivated not only by industry trends, but also by the potential to swiftly provide business value. By embracing the cloud, we gained access to managed services that allow us to concentrate on the core aspects of DXP. Although these services can pose certain cost challenges, the overall advantages and the capacity to effectively manage expenses through proper implementation make the cloud-native approach superior in our eyes.
But, back to the incident story. What the June cost overkill really taught us was that the way we work around the product is just as important as the product itself.
When we started working on StreamX, we introduced a general rule: for services we need more control over, and need to deploy locally - Apache Pulsar, Grafana, Ngnix - we use our own services.
For data services like logs, artifact and bucket repositories, we decided to use managed services instead of deploying them to our own cluster. This strategy lets our engineering team focus on the core of our DXP, but it also requires putting practices in place to prevent unexpected spikes in resource usage.
The cost issue we were facing was discovered in one of the managed services, the log ingestion (indexing) - records that applications generate as they work. StreamX is designed to handle millions of events. So the volume of logs was quickly becoming a problem. We had automated tests and KPI checks that triggered loggers to produce entries, and these tests simulated traffic. And at 50 cents per 1GB, the terabytes of log data we were generating were costing us a lot of money.
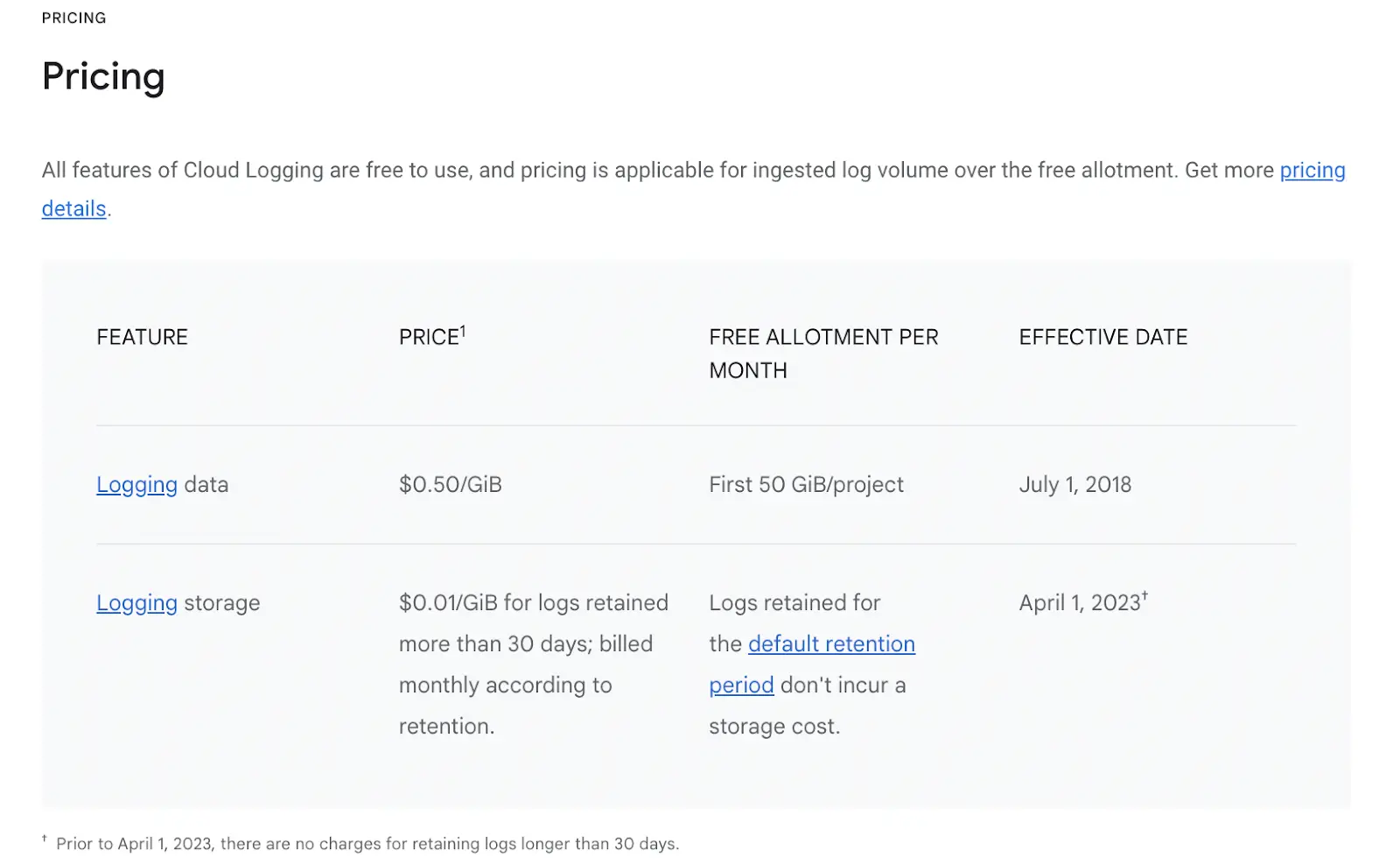
In Google Cloud, logging storage is 50 times more expensive than logging data.
If we had done this the traditional way, without using the cloud-native approach, we could have stored the logs in an on-premises solution, which would have been less expensive than the cloud-managed service. However, at the log volume we are generating would most probably run out of disc capacity, causing a service crash.
Beyond the crash resilience, managed services have another advantage that we were not willing to give up, given the agility, speed, and developer-led nature of our team: they are ready to be used straight out of the box.
Therefore, we chose to stick to them, and fine-tune every aspect until we were fully satisfied with the cost forecast.
The first step was to reassess what our needs actually are, and plan our action accordingly. The DXP team’s work schedule emerged as a crucial factor, given the clear pattern in resource usage during different development phases.
Resources used heavily when peak
No resources used when no publications
WebServers are client-facing (serves static pages), must be available 24h/7
Rest of DXP components use resources only during publications
resources used only when authoring happens (8:00 - 18:00 Mon - Fri)
Ingress controller, monitoring, etc. - critical for the platform, must run 24h/7
We started by implementing some quick wins to handle the incident:
"pausing" the environment by scaling down workloads that end-users are not interacting with (all but WebServers)
reduce event-level log entries in favor of monitoring
optimized resource usage
using spot VMs whenever possible
After that, we wanted to ensure that similar problems wouldn't occur in the future. So, we focused on automation to prevent such incidents. We started with automating more detailed alerts to notify us quickly if something goes wrong. We identified potential issues and incorporated them into the alert system. This covers the operational aspect of total cost of ownership.
We introduced:
auto-scaling for all workloads (it’s still a work in progress)
Kubernetes cluster autoscaling to provide new nodes when needed and pick unused nodes back when not needed
On-demand environment pausing/unpausing
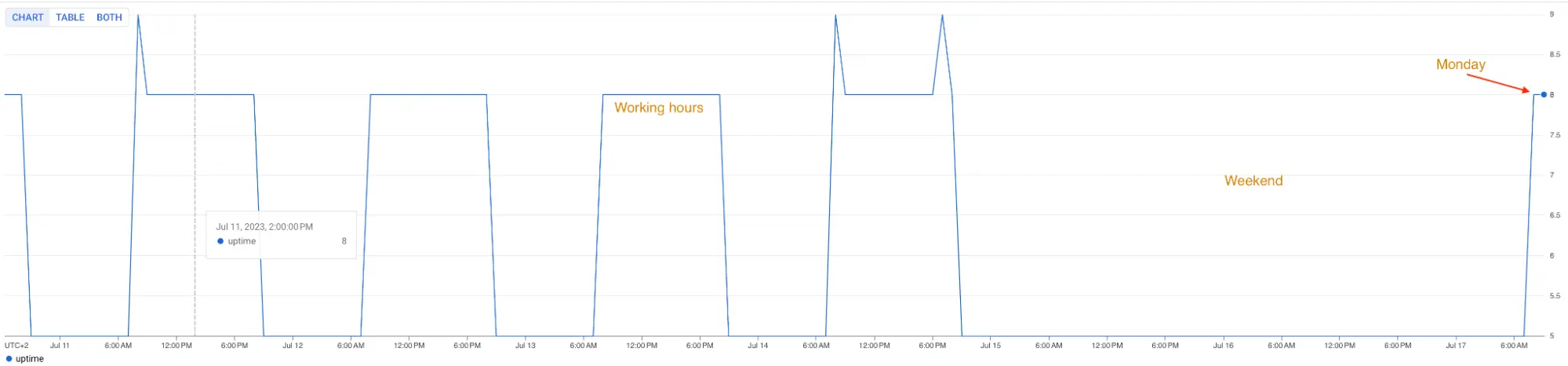
GCP Monitoring - number of working K8s nodes in week
These long-term solutions are what we anticipate will optimize our cloud usage the most. So let's dig a bit deeper into the logic behind our decisions here.
The first thing to understand here is that infrastructure costs are not only applicable to production environments. They also impact other types of environments:
development environments (development)
test environments (manual tests)
perf environments (performance tests)
int environments (integration tests)
staging environments (pre-production environment)
Some of those have to be long-living. Some can be on-demand/ephemeral. In development, we use short-lived environments that can resemble production environments in terms of scalability. For example, we can utilize cheaper machines like spot instances, which are 70% cheaper but can be taken away by the cloud provider at any time. This is acceptable if used for development purposes only.
We can also spin off multiple short-lived environments for a few hours and then destroy them. This reduces costs during the development phase. We also maintain longer-lasting environments, such as staging, which are not continuously in use but need to be kept ready for when they're needed. For these environments, we have developed different models.
GitHub Actions - automated steps for environments
One approach here is to scale down certain parts of the application that are only used during business hours. By automating this process, we can shut down the application and associated servers during off-hours, reducing costs. When the team comes back to work, we spin up the servers. This is a composable approach that optimizes costs based on usage patterns.
Fun fact - thanks to StreamX's push model, we're even able to shut down the CMS when it's not needed for runtime. In StreamX, the CMS is only used to create content, and once the content is published, it can be safely switched off.
In our product development process, incidents like the one described provide valuable insights. We always consider how similar incidents could occur on the client's side, so we take steps beyond mere incident resolution. Our aim is to leverage our knowledge and create a blueprint for future StreamX implementations.
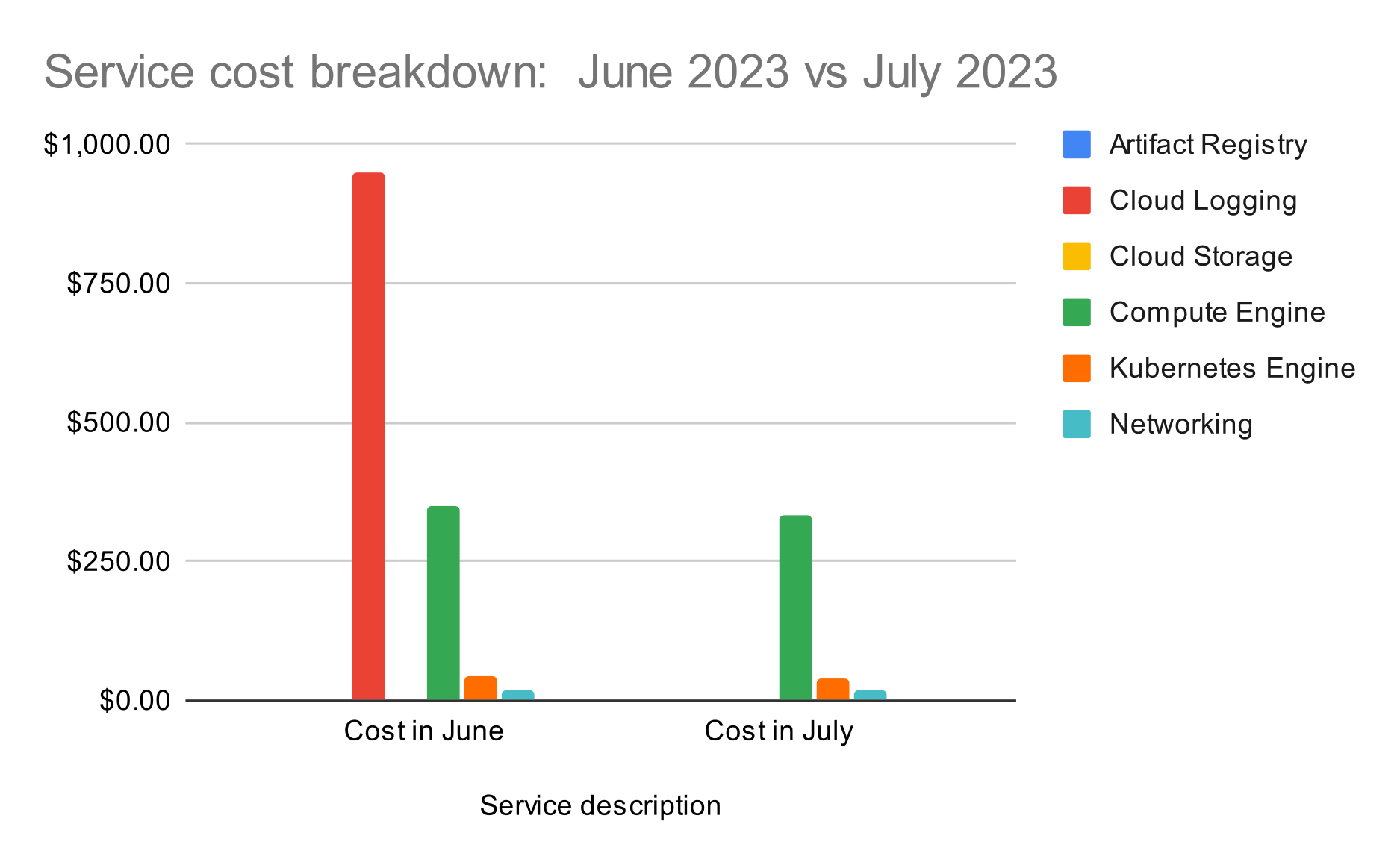
Service cost breakdown before and after optimization
When building StreamX, we prioritized both the end product and the developer experience. Automation is a key focus here, ensuring that developers can easily adopt the practices we follow every day. Basic operations like stopping servers, or creating new environments should be simple and automated. As requirements become more advanced, additional skills may be necessary. However, we strive to make the starting point and basic operations accessible and straightforward.
We consider infrastructure scalability to be a critical factor in our platform advantage. Every business experiences periods of high traffic, such as during events like Black Friday, as well as periods of lower activity. Our platform is designed to intelligently manage resources, rather than constantly being prepared for peak traffic. We continuously optimize it to dynamically respond to actual traffic, scaling up or down as needed.