
by Michał Cukierman
9 min read
by Michał Cukierman
9 min read

Imagine a factory that suddenly receives a large, unexpected order. It might struggle to meet this sudden demand due to its unprepared production line. Traditional Digital Experience Platforms (DXPs) face a similar issue when they encounter a rapid increase in data traffic.
Their stiff and unchanging architecture lacks the flexibility and ability to grow that's needed to handle such situations. For a website, handling high demand is a crucial moment that requires constant readiness. It’s a marketers nightmare to have your months-long Black Friday campaign preparation end in a site crash.
Modern platforms should always be prepared to handle an increased load and must do so cost-effectively. However, the application's ability to grow within a single-unit architecture is usually limited by the hardware and infrastructure restrictions of the system.
Traditional DXPs have tried to overcome this problem by creating distributed systems from single-unit applications and complex data replication mechanisms. While this solution was advanced when it was created, it now struggles to keep up with newer technologies like rapid cloud adoption, serverless computing, application containerization, and microservice architectures
To better understand the DXP scalability issues, we first need to define what scalability is. There are two main ways that we can increase the size of applications:
Vertical scaling: when we add more resources to a single machine to handle more load.
Horizontal scaling: when we add more machines to a system to share the extra load among them.
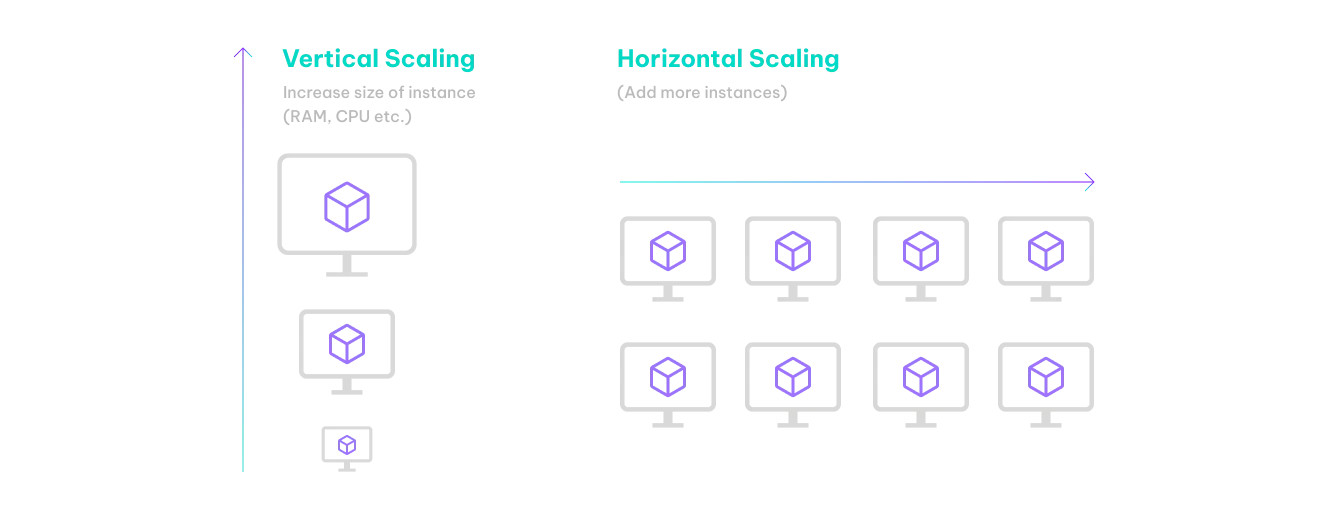
Figure 1: Horizontal and vertical scaling
In practice, vertical scaling is like moving to a more powerful machine, or adding resources if you are using a virtual system. This is easy to do.
Horizontal scaling often needs data to be spread out between systems. This can only be done by copying data or by sharing common data stores, making the task quite challenging, especially for big deployments.
Aside from increasing the size of the platform as needed, it's important to be able to change the size of the cluster based on the actual load. In technical terms, this is called system flexibility. It should be possible to make the system larger when there is high demand, and make it smaller whenever possible to avoid unnecessary use of resources. Idle resources can be very costly, so it's very important to change the size of the system dynamically based on demand.
To get the most out of the scaling capability, it has to be automated. Both horizontal and vertical scaling should react to resource requests or scaling triggers, which could be a certain number of simultaneous requests or CPU loads during a specific amount of time. This should not require a person who monitors the system and manually scales it.
Another important part of scaling is the underlying infrastructure provisioning. Most cloud and hosting providers support automatic provisioning and resource management. To effectively grow or to save money from reducing infrastructure size, the platform needs to use technologies that can make intelligent decisions about resource management.
Why is automation so important? It can be tested, it can be repeated many times, and it can be measured, improved, and versioned. With automation we can eliminate human errors and, most importantly, it's fast. Time needed to scale, especially when there is high demand, is very important for systems. Optimized containers and serverless functions need milliseconds to start additional instances. If the service stores its own data, this should happen in seconds.
However, when increasing the size across different regions, where you need to copy data between geographic locations, it can be difficult without fast networking between clusters. Multi-regional deployments become even more complicated for monolithic applications, which is why the platform should be designed to handle growth using distributed, lightweight services.
Another thing to consider is how linear your scaling is. If you duplicate processors and memory, your application's performance should ideally double. The same should apply for horizontal scaling. If you double the number of nodes, the performance of your entire platform layer should also double. Is linear scaling possible to achieve? Yes, but it requires the elimination of all system bottlenecks. If even one system element doesn't scale linearly, the entire system will lack this characteristic. The bottlenecks could be for example:
single application node responsible for content replication, like an authoring node distributing the content to publishers
system integration, where data is loaded and processed on one machine
shared resource such as a database or file system storing the data available to all nodes
Modern platforms offer the possibility of creating systems without these bottlenecks. The widespread adoption of cloud-based systems has been a major contributor to this improvement. If the underlying infrastructure is no longer a limitation, the platforms running on the cloud should not have those limitations either.
Fault tolerance is another key factor. In a platform that is both vertically and horizontally auto-scalable, the system should automatically detect errors and respond to them. If nodes break, they should be removed and recreated, and persistent data should be redundant. Even if an entire data center goes offline, the system should continue to operate in the remaining availability zones or regions.
So, how well do traditional DXPs handle scalability? Usually, the authoring layer can only be scaled vertically. It's therefore common to increase the machine size, or assign more resources over time. The underlying reason for this is the monolithic architecture with a single transactional database, which is hard to replicate and still supports data consistency. Some vendors allow the scaling up of author nodes by creating a cluster with a shared data store, but this requires advanced administration and operational skills.
The publishing layer can be scaled both horizontally and vertically, as each publishing node usually contains its own data store. Content is replicated from the author to publish nodes using a push model, and publishers don’t know about the existence of the author node. User Generated Content (UGC) is replicated between publishers via reverse replication (from one publish node to the author), followed by forward replication (from the author to all publishers). In some variants of this, publishers can synchronize the content directly between themselves.
Dispatchers, acting as HTTP cache servers, are usually paired with publishers, but multiple configurations are possible. There's no need to distribute any content to and from the dispatcher, and it can relatively easily be scaled vertically and horizontally.
Monolithic architecture was developed before the cloud era, so a DXP cluster is typically manually created and has a fixed size and configuration. Its topology is designed in response to expected traffic estimations, and isn't changed too frequently. The scaling process is complex, involving multiple steps.
The author node must know each publisher in order to distribute data during content publishing. It is responsible for managing the replication queues used to distribute content, and for ensuring the eventual consistent state of a cluster. If one or more publishers are unavailable, published content must be stored in the queue and redelivered when the target node becomes available.
Adding a new publisher is particularly challenging, because the new node needs to reflect the state of the rest of the cluster publishers. This is not a trivial task, especially when one of the existing publishers needs to be put offline and cloned to a new machine, and content can be changed during this operation.
Furthermore, the scaling operation can be automated, but it involves multiple steps, and things can easily go wrong. The whole process takes a lot of time, making it hard to respond quickly to traffic peaks.
In this case, the delta must be applied to both instances after cloning. Once the new node is available, the author needs to be informed of it and start distributing content to it. If a new dispatcher was created along with the publisher, it must be paired. Otherwise, one of the existing dispatchers must be informed of the new publisher. Finally, the load balancer needs to know the address of the new dispatcher in order to add it to the load balancing group.
This entire scaling operation could be automated, but it involves multiple steps, and things can easily go wrong. The whole process takes a lot of time, making it hard to respond quickly to traffic peaks.
The big drawback of this process is that one of the publishers must be taken offline before cloning, which reduces system throughput at the worst possible moment. Of course, it's possible to have an extra publisher that's not connected to the load balancer, but this increases cost and complexity. That's why most organizations stick with fixed-size clusters.
Multi-region setups work well as long as the content is only distributed from the author to the publishers. If the site uses UGC, synchronizing content between regions can be overhead. In cases where data needs to be synchronized between regions, the extra latency or irrelevant content can break the overall user experience.
In traditional DXPs, scaling isn't linear. The authoring instance, responsible for content distribution and managing replication queues, can become a bottleneck. The more publisher nodes in a cluster, the more complex and time-consuming the synchronization of User Generated Content (UGC) between them becomes.
The thing that cannot be scaled horizontally is the database (a content repository) used by a single publisher or the author node. DXPs tend to grow and become slower over time because they accumulate a lot of historical data, like old pages, packages, applications, workflows, versions, or unused binary assets. CMS repositories have limited capacity and aren't designed to be web-scale. Regular data organization and cleanup is often a challenge for organizations.
Scalability is crucial in today's world. Poor scalability can result in problems like:
Difficulty handling traffic peaks, which could cause a system to go offline during peak demand.
High infrastructure costs, especially if there is no auto-scaling. Fixed-size clusters generate costs even when they are underused.
Missed opportunities if a platform has reached its scaling limits and is operating at full capacity.
The operational risk of managing complex, manually configured clusters.
Increased maintenance costs due to an overgrown repository of data.
DXP platforms should drive innovation, but this isn't possible with limited scalability and throughput. Companies are often turning to other solutions to replace DXP, but the answer should rather be a DXP done right.