
by Michał Cukierman
6 min read
by Michał Cukierman
6 min read

In a legacy deployment setting, each software application is installed on dedicated physical servers. Each server has its own operating system, software libraries, and hardware resources.
This approach, although tried-and-tested over the years, comes with numerous pitfalls. It's resource-intensive, costly to manage and scale, needs manual upkeep of multiple servers, and hardware failures can result in significant downtime.
What's more, the legacy deployment model often leads to underutilization of server resources, as each server is only running a single application. It's still more cost-effective to have an application on a server with more resources, rather than perform a migration to new servers at the least expected time. Underutilization is costly but overutilization may result in system crashes.
Traditional Digital Experience Platforms (DXPs) are typically distributed systems designed around monolithic applications. They have historically been implemented on bare metal servers, or (later) virtual machines - a conventional approach that's now seen as a relic of an earlier computing era. Does it still remain a viable option?
To address issues related to hardware dependency, companies have adopted virtualization. Applications began to be installed on virtual machines instead of physical servers, and managed by dedicated software. What’s important, shifting to virtual machines didn't require changes in application code, easing the adoption of DXPs setups. This modification made vertical scaling much easier, because virtualized resources assigned to the machine are a part of the configuration. What’s more, hardware failures didn't cause as much downtime as before.
Unfortunately, the switch from bare-metal servers to virtual machines didn’t significantly impact the monolithic application lifecycle. Server setup still required all dependencies and applications to be installed on the server. Post-installation, maintenance and administration tasks were carried out on the same instance. These tasks could be for example:
Application upgrades (publish or author instance upgrade)
Application modules deployments (project-related deployments)
Configuration changes (both servers and deployments)
Data changes
Data cleanup, maintenance tasks
Operating System updates
Dependencies update
The catch here is that all these changes impact the shared server and application state. I have seen many DXPs that were installed over 10 years ago, and maintained in one place from the beginning. After so many years, it's really hard to tell what's happening and what's been done on a server. We are faced with a situation where everything is running, but no one really knows how.
Over such a long time, it becomes increasingly difficult to understand the server state, especially when data, configuration, and code aren't distinctly separated. Manual server modifications further complicate the situation, with such changes often not tracked or versioned. Recreating the state of an instance, if needed, could then become an impossible task.
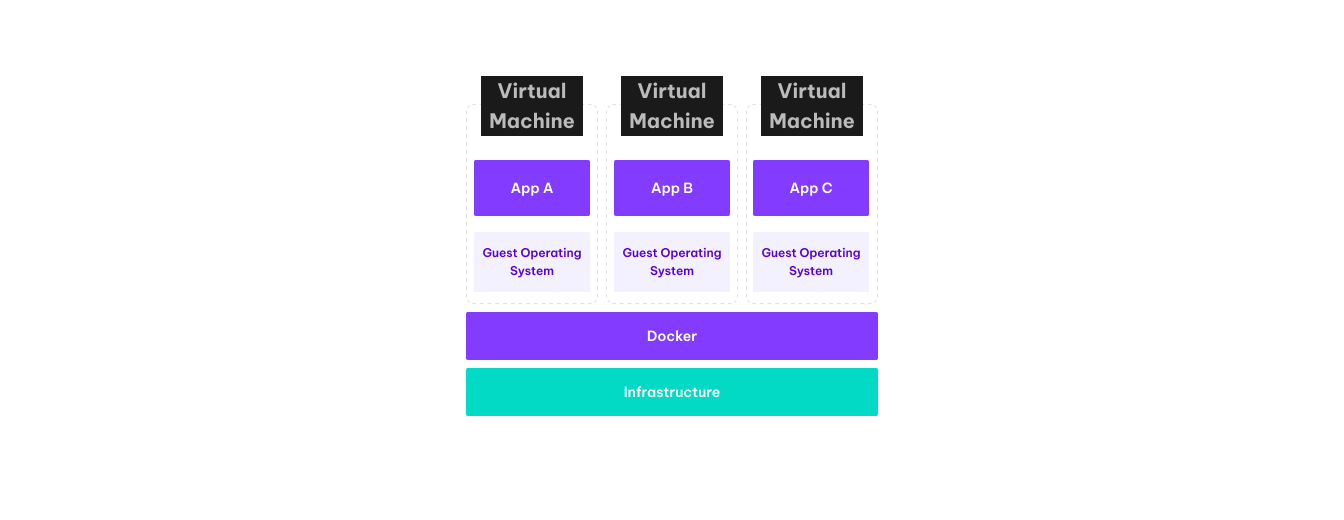
Figure 1. Virtualization using hypervisor
Container-native applications seem to address the challenges associated with legacy deployment models. Replacing long-leaving application servers and persistent disks, with lightweight and immutable containers and ephemeral storage. Containers use persistent volumes only for specified directories. Immutability means that any changes made to a container are lost upon restart, making each new container a clean slate.
These containers are lightweight, so they can be easily exchanged and shared through a common repository. Once pushed to a repository, they can be used by other team members, or moved through testing and deployment pipelines up to production. This method ensures that the production environment mirrors the local or development environment, providing a critical consistency for application deployment.
The ability to share entire containers eases both automated and manual testing processes. It helps with deployments too. In case of a failure or bug discovery, it's simple to roll back to the previous version. This is especially important in complex clusters operating tens or thousands of containers, where the whole process can be orchestrated.
For the data that needs to survive containers restarts, the persistence must be explicitly configured. You must decide which directories should be preserved. Typically, persistent volumes are defined on containers that are used as data storage in the cluster.
With containers we can also achieve advancement in configuration management. If the configuration is common for all environments, it may be a part of the container image. If the configuration varies between environments, system variables or secrets, provided by orchestration engines like Docker or Kubernetes.
These orchestration engines provide a range of features:
Containers deployments management
Services scaling to meet changing demand
Resource balancing to optimize performance and utilization
Incoming and outgoing traffic management
Security management
Background job management
Persistence management
The list is certainly not complete, in part because it's possible to provide custom extensions to the engines and bring new functionality. Some interesting ways I've used Kubernetes recently are automated management of SSL certificate provisioning and DNS management.
The last part to make the picture complete is the CI/CD pipelines, as they bring automation to the forefront of application delivery. They automate different types of testing, releases, and deployments across different environments with a blue/green or canary approach. Pipelines also manage the deployment of ephemeral environments and the setup of long-lived environments. When applications are designed optimally, it's a very efficient way to operate.
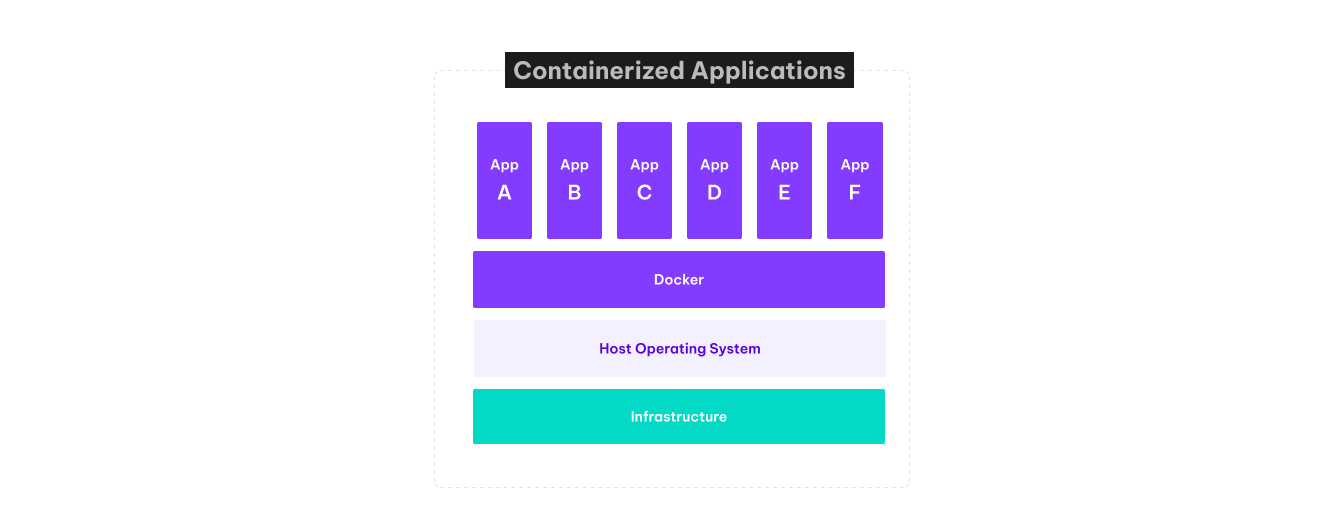
Figure 1. Virtualization using hypervisor
Unfortunately, many traditional DXPs still rely heavily on classic setups on virtual machines. Despite vendors claiming to support containerization, I’ve only seen a few successfully demonstrating a cloud environment operating on containers. The challenge lies not in running legacy applications in a container but in transforming them into container-native ones. The simple test would be to ask a vendor to set up a local environment. If it takes more than minutes, the product is probably not cloud ready, at least if it’s a setup based on containers.
I’ve spent too much time during manual deployments or on calls with key people from the technical teams trying to fix and recover the platform from a crash or error.
I’ve faced too many issues to be able to bring all of them, but some problems with traditional DXPs, that are worth noting are:
Complex and risky, multi-step manual deployments
No standardized and repeatable rollback plan after deployments
Problem creating lower environments from production or matching production
Hard to update lower environments with actual data
Unknown applications state. Hard to create a disaster recovery plan
Unknown applications state. Part of errors can only be found on production
Lack of proper monitoring and observability tools
Expensive infrastructure with often unutilized resources
No auto-recovery when an application fails
Long processes required to deliver hotfixes
People are spending a lot of time creating local environments
Local environments not matching the production environment
For innovation to thrive, teams need to be confident in what they deliver. A stable, easily maintained, and reproducible platform fosters faster development and lowers operational costs. Unfortunately, most traditional DXPs do not meet these criteria, and companies that cling to them risk being left behind in the face of technological advancements. Therefore, the need for change and evolution is more pressing than ever.