
by Michał Cukierman
10 min read
by Michał Cukierman
10 min read

Having site search is a common requirement, especially when a project runs on a fully-fledged Digital Experience Platform (DXP) that provides this functionality out of the box.
The situation becomes more complicated when the search has to be aware not only of the authorable page content but also data from other systems like PIM or ecommerce. There are two choices: the simple approach is to load all the data into the DXP and leverage embedded search, while the ambitious approach is to integrate all the source systems with an external search engine.
Digital Experience Mesh offers a third opportunity - it enables you to utilise real-time data pipelines to transform raw data into meaningful search experiences. In a scalable, performant, and secure way.
Search experience across sites can have a significant impact on a business across several key areas. Depending on the industry, it may affect:
Conversion Rates: Customers who can't find what they're looking for are more likely to abandon their search and head to a competitor. Inaccurate or outdated search results lead to frustration and a missed opportunity to convert potential customers into paying ones.
Customer Satisfaction: A clunky search function creates a negative user experience. Imagine struggling to find a specific product or facing irrelevant results. This leads to dissatisfaction and can damage customer loyalty.
Brand Positioning: A seamless search experience reinforces a brand's image of being user-friendly and knowledgeable. Conversely, a poor search function undermines brand positioning and makes you appear outdated or unorganised. A smooth and intuitive search experience is something that customers expect, and lack of it may lead to frustration.
Of course, happy customers are essential, but a powerful search function also needs strong technical and operational foundations.
Implementation Costs: Implementing data ingestion can be expensive. Integrating with third-party search engines often involves multiple system-to-system integrations. Loading all data into the DXP can be equally time-consuming, especially if integration results fall short and require multiple iterations.
Security Concerns: Exposing embedded DXP search functionality requires the DXP search endpoints to be publicly accessible. Unlike dedicated search engines, DXPs often store sensitive data like user information, which could be compromised if not properly secured.
Time-to-Market Delays: Building a custom search solution from scratch can significantly delay launches. Data ingestion and synchronisation can be intricate, impacting time to market.
System Availability and Performance: Out-of-the-box DXP search engines can put a lot of stress on servers. Search endpoints don't leverage caching and may struggle under heavy web traffic. That will affect other areas where the DXP is involved like web delivery.
Limited Flexibility: Replacing search engine providers with a different solution can be challenging due to tight integrations between source systems and the existing search engine.
While site search seems straightforward, incorporating data from various sources like traditional or headless CMS, PIM and ecommerce into search results is a complex technical challenge. Let's break it down into two key areas: data ingestion and search query execution.
It’s important to choose which data are relevant and should be stored into the search index. It’s important to decide how to perform Data Extraction and Transformation. Extracting data from multiple sources in different formats requires custom processes. Data may need cleaning, transformation, and standardization before feeding it into the search engine.
Extracted data may be sent to the search index in Real-Time or using Batch Updates. Balancing the need for real-time search results with the ease of implementation of bulk data updates can be tricky.
The last, but maybe the most important consideration is defining the system which is responsible for Data Management. It’s important that the system is highly available and performant, because it can be a bottleneck of your data ingestion process. The system will work as the source-of-truth for the search experiences. In some cases architects decide to replace this responsibility with multiple systems to search index (or indexes) integrations.
Such a decision may lead to problems with defining what data are indexed and in what state, it can be problematic to synchronize the data as well as providing consistent scoring results (example situations are products with prices different than during the checkout, or search results of pages which were not published yet).
Monolithic repository: Loading all the data into a single database or repository and index it in batches.
ETL (Extract, Transform, Load): A traditional approach involving extracting data from source systems, transforming it to a format suitable for the search engine, and then loading it into the search index.
CDC (Change Data Capture): A more efficient method that captures only the changes made to source data, minimizing the amount of data transferred and processed. This technique, together with event streaming, enables continuous data ingestion and updates, ideal for scenarios requiring highly up-to-date search results.
In simple words, we need to define where the search indexes should be managed. A couple of popular options are:
Embedded Index: The simplest approach is to use a search index embedded in the CMS or DXP. This drastically reduces the initial implementation costs. It requires no connectors, or additional services. Unfortunately, the search results quality is limited, performance depends on the CMS load and the scalability is very limited (as the whole CMS has to be replicated to scale single search functionality). This is the easiest and the most limited approach.
Multiple, distributed search indexes: It’s possible to deploy multiple Search engines and deploy them in various geographic locations to provide multiple small instances of search engines with all the data available locally. This option isi most flexible and can provide superior performance.
Search Engine cluster: The last option is to employ a dedicated search cluster or even use a SaaS based cluster. This is a preferred option for large datasets, where the replication and scaling of this layer is the search cluster responsibility.
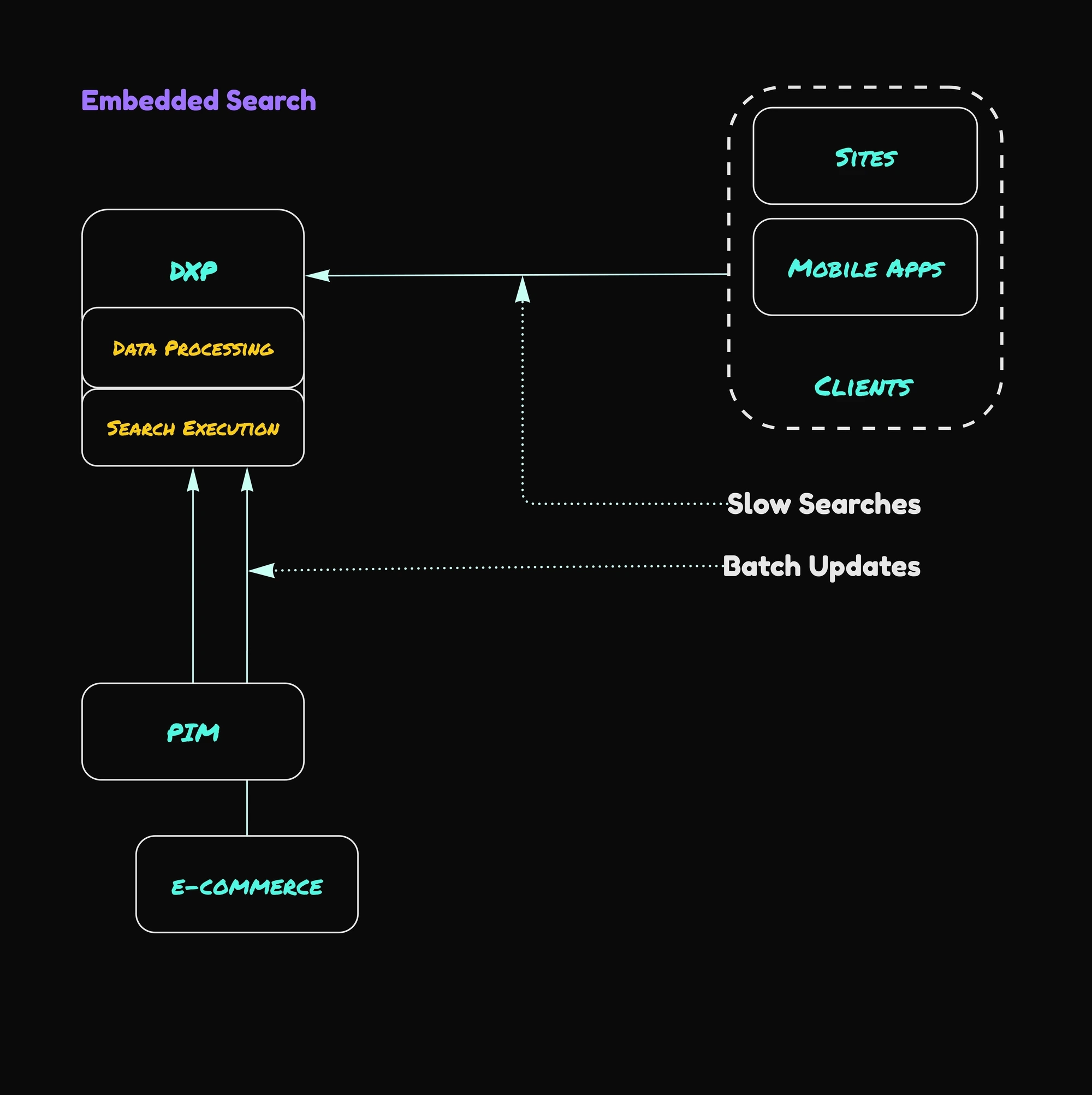
DXP embedded search
While loading all content into the DXP repository seems like the simplest way to enable search, this approach has limitations. It might work for basic websites where content solely resides in the CMS. However, things get complex when multiple systems are involved.
In this scenario, the DXP shoulders the responsibility of data ingestion. But the key question is: how do PIM and e-commerce systems notify the DXP about data changes? Often, this relies on lengthy batch jobs involving data export from other systems and subsequent import into the CMS.
The critical issue here is that the CMS repository isn't designed to efficiently store structured data like product details or stock information. This can lead to performance bottlenecks and data management headaches.
However, limitations exist beyond data ingestion. Search experience when using embedded indexes suffers as well. These built-in search indexes store all (or most of) repository data, serving both content authors searching for assets or page references and website visitors performing searches. This multi-purpose usage can lead to slow performance and provide worse results.
Furthermore, embedded search lacks the advanced functionalities offered by dedicated search engines – systems solely focused on delivering exceptional search experiences. Additionally, embedded search scalability poses a challenge. While a dedicated search engine can be scaled independently, scaling embedded search requires scaling the entire DXP node, most commonly a publish instance.
Finally, embedded search can seriously impact DXP performance. Complex search queries executed by website visitors can significantly slow down the entire platform. However, an even greater security concern is the potential for malicious actors to exploit these limitations and launch DDoS (Distributed Denial-of-Service) attacks. These attacks overwhelm the DXP with a flood of search requests, rendering it unavailable to legitimate users.

External Search Engine
An alternative architecture leverages an external search engine. In this approach, all systems send their data directly to the search engine. While this introduces complexity due to the need for multiple connectors, it offers several advantages.
Scalability: The search engine can be scaled independently to handle increased search volume, ensuring smooth performance.
Performance and Availability: Search performance and availability become independent of the DXP's health, preventing cascading issues.
Advanced Features: Customers gain access to the latest search engine functionalities, including AI-powered search capabilities for enhanced user experiences.
While external search engines offer advantages, challenges arise in data synchronization and management.
Data Consistency: Ensuring all systems send synchronized data to the search engine can be difficult. For instance, a product without a published product detail page (PDP) might be searchable because its information from another system hasn't been processed yet.
Data Selection: Determining which data gets indexed requires careful consideration.
Schema Definition: Defining a unified schema for the search index can be complex, often leading to data composition happening on the frontend. This can hinder the ability to deliver high-quality search results with accurate ranking.
Connector Complexity: Implementing and maintaining multiple connectors to the search engine can be intricate. Ideally, these connectors should have features like queuing indexation requests and retrying failed indexing attempts.
Lack of Experiences Orchestration: The lack of a central point managing data processing logic can lead to inefficiencies and inconsistencies.
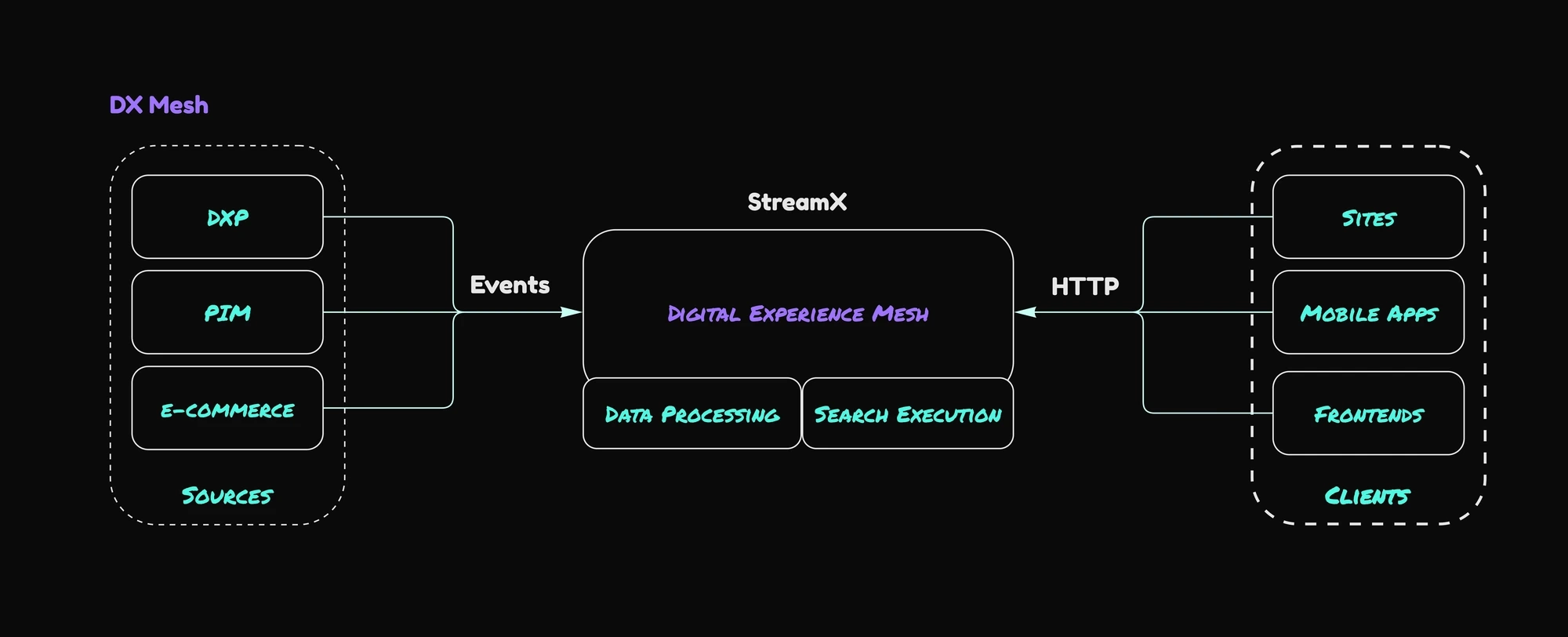
Multi-source search in StreamX
The limitations of both embedded search and relying solely on external search engines highlight the need for a more robust solution. StreamX Mesh addresses this by reacting to relevant updates from all source systems (PIM, e-commerce, etc.) in real-time. These updates are transformed using data pipelines and pushed into the Unified Data Layer. StreamX leverages a dedicated search engine within the Data Layer, offloading search functionality from the DXP. In addition, using StreamX helps you to achieve:
Enhanced User Experience: StreamX Mesh empowers you to deliver a richer search experience by integrating with advanced search engines. This allows you to leverage features like faceted search, advanced filtering, rankings, and AI-powered search functionalities, enabling users to find exactly what they need quickly and easily.
Unmatched Scalability and Performance: StreamX Mesh employs a decoupled architecture, separating data ingestion and search execution. This allows you to scale the search engine service independently to meet growing demands without impacting DXP performance. This ensures a smooth and responsive search experience even during peak traffic periods.
Composable Architecture for Future-Proofing: StreamX Mesh embraces a composable architecture. This means you can easily integrate different best-of-breed components, like search engines or data sources, without complex modifications. This flexibility allows you to adapt your search solution to your evolving needs and technological landscape, ensuring a future-proof architecture.
Always Up-to-Date Results: StreamX Mesh utilizes real-time data pipelines to ingest updates from all connected source systems. This ensures your search results are constantly in sync, providing users with the most accurate and relevant data at all times.
Traditional search solutions for DXP, whether embedded or external, struggle with limitations. StreamX Mesh offers a powerful alternative. It listens for updates from all your systems (PIM, e-commerce, etc.) in real-time, transforming and storing the data for efficient search. By leveraging a dedicated search engine and a composable architecture, StreamX Mesh delivers unmatched scalability, performance, and a future-proof approach. This translates to a superior user experience with features like AI-powered search and always up-to-date results.
Integrate real-time data from multiple sources into your AEM
for a superior search experience that boosts conversions satisfaction.