
by Michał Cukierman
4 min read
by Michał Cukierman
4 min read

Imagine running a pizza spot and having one big, heavy truck that’s used to transport ingredients in the morning, run errands during the day and deliver each individual order. This method works well when demand is low. But when orders surge, your truck struggles. It gets stuck in traffic, causing delays. Gas and maintenance costs kill your sales margin. "But a single truck is not designed to handle every aspect of a pizza business” you might say. Well, that's exactly right.
This pizza delivery scenario mirrors the problems found in traditional Digital Experience Platforms (DXPs). Originally built on monolithic architectures and transactional databases, these platforms focus more on collaborative authoring work and publishing the content, rather than handling high-traffic volumes or real-time interactions.
This design flaw results in low throughput, most noticeable (and most annoying to customers) in high-demand platforms such as e-commerce sites, concert ticket booking platforms, airlines or FMCG online retailers/.
Throughput is a measure of the quantity of information a system can process within a given timeframe. In the context of DXP use cases, the throughput might refer to the number of units processed per second, for example:
# of complete pages served to the end users
# of pages that can be published and replicated across the platform
# of renditions created from the assets
# of entries processed to generate recommendations using ML
As DXPs were not originally engineered with performance as a priority, they tend to get overwhelmed quickly when faced with heavy demand. A single publish node installed on a multi-core host machine can serve only tens of requests per second.
Other limits can be hit easily as well. It’s relatively simple to block a replication queue by publishing too many pages or assets, or to overload the servers by uploading too many assets at once, which triggers long-running background jobs. When we need the system to operate at scale and remain responsive to user-generated events, is when the limitations become painfully apparent.
Each one of the leading DXP platforms has mechanisms in place to work around (or sometimes outright hide) the throughput issues.
Some of these mechanisms involve offloading jobs to handle assets, while others distribute tasks across multiple nodes to increase processing power. Traditional DXP platforms also rely heavily on various caching techniques, including HTTP cache servers or content delivery networks (CDNs). However, maintaining a distributed system can be problematic: the more nodes there are, the more data needs to be transferred, leading to potential data conflicts, including simultaneous content updates.
Additionally, there is still a single point of failure - the node responsible for managing replication.
As a Netscape engineer Phil Karlton once said: “There are only two hard things in computer science: invalidating caches and naming things". Having faced both of those problems, I have to say that cache abuse tends to have more severe consequences.
It's very common to say that a well-designed site should have 100% cacheable content. I've been a DXP architect for years and this was one of the main rules I had in mind when designing a new system. But why is it so important?
The cached content on the dispatchers or CDN is the only part of the system that can handle the traffic. Dispatchers are stable, secure, provide consistent response times, and are easier to scale than publishing nodes.
But relying on the cache raises another question: What happens if it becomes unavailable after deployment or content publishing? In the worst-case scenario, the system faces downtime. In the best case, it suffers slow response times and client drops. Both scenarios are all too common.
Other caching issues include over-caching, leading to system failures, or under-caching, leading to server crashes during periods of high demand (e.g. during a campaign launch).
Also, not all content is static and cacheable. In a pull model, it's common to make calls to underlying databases or systems to get the data needed for a response. Caches cannot be used in this situation. The whole system depends not only on the DXP servers, but also on external data sources. These dependencies become potential points of failure that should have been minimized.
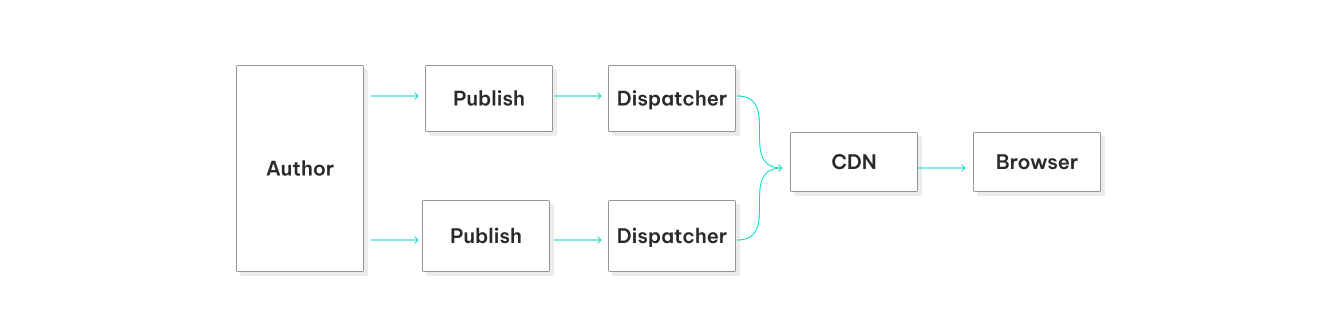
Figure 1: Performance per traditional DXP delivery layers
In the end, just as our pizza business would need to change to serve a larger customer base, so must our digital platforms.
To effectively handle high traffic volumes and real-time interactions, we need to move away from traditional architectures towards more efficient, scalable, and robust solutions. It's time for our DXPs to go from delivering pizzas one-by-one with a fleet of food trucks to a highly efficient model that can cater to the entire city at once.
Traditional DXPs handle a handful of orders at a time, but this number pales in comparison to the tens of thousands of concurrent requests that non-blocking, event-based servers with event-loop implementation can handle using the similar infrastructure.
Learn more about how throughput works on StreamX.
In conclusion, poor performance and low throughput can lead to several issues including:
Issues with handling high visitors traffic
Platform stability issues after cache flush caused by deployments, publications, or by requests bypassing the cache
Cache overuse, which can result in exposing sensitive data or serving outdated content
High response times when the content is not cached
Problems with delivering relevant experiences, requiring extensive data processing
Fragile architecture with multiple points of failures
Larger infrastructure costs